
לפני כמה שנים, כשהתחלתי את קריירת הפיתוח שלי, איך בוחרים Database, לאתר החדש שבניתי או לאפליקציה, לא הייתה משימה מורכבת מדי, כמו להחליט על הקפה שאני שותה במשרד בבוקר, שחור או… שחור. אף אחד לא חלם על מכונת אספרסו שתכין לי קפ׳וצינו.
נכון, היו לא מעט חברות בשוק, עם לא מעט הבדלים בין מוצר למוצר אבל בשורה התחתונה, רוב המוצרים נתנו גרסה כזאת או אחרת של Database רלציוני או בקיצור RDBMS – Relational Database Managment System.
בנוסף, אם כבר עבדת עם מוצר מסויים, רוב הסיכויים שהייתם פשוט בוחרים בו. אם זה משיקולי עלות (או העדר עלות במוצרי OpenSource כמו MySQL), הכרות הצוות עם המוצר, כלים שכבר פיתחתם או השתמשתם בהם וכמובן שיקולי מהירות פיתוח. בקיצור, בדיוק כמו קפה שחור של עלית. שותים אותו לא כי הוא הכי טעים אלא בגלל שהתרגלנו.
אני התחלתי עם Microsoft Access (לא לצחוק, זה היה RDBMS לכל דבר מאחורי הקלעים, עם ממשק פיתוח גרפי יחסית נח לאותה תקופה), לאחר מכן עברתי ל – MSSQL, כמה שנים עם Informix (נקודות בונוס למי שמכיר/עבד איתו) שהוחלף על ידי Oracle RAC, גרסת ה – Cluster של Oracle, אבל את רוב שנות הפיתוח וניהול הפיתוח שלי העברתי עם MySQL (וקצת MariaDB אחרי ש – Oracle רכשה את MySQL).
איך הכל התחיל?
בתחילת הדרך (שנות ה – 70 של המאה הקודמת), מנועי RDBMS עוצבו על מנת לקחת כמויות גדולות של נתונים ולעשות אופטימיזציה על המקום הדרוש לשמירתם. הסיבה המרכזית לכך הייתה העלות של כל GB (או אפילו MB בתחילת הדרך) של דיסקים.
אם רציתי לשמור רשימת עובדים בטבלת employees (לצורך הדוגמא מס׳ עובד, שם פרטי, שם משפחה ותפקיד), במקום לכתוב את התפקיד של כל עובד בשורה אחת עם שאר הפרטים שלו, בניתי טבלה נוספת בשם jobs, עם כל התפקידים בחברה ו – id לכל אחד מהתפקידים ויצרתי קישור בין טבלת העובדים employess לטבלת jobs ושדה מקשר job_id בשתי הטבלאות.
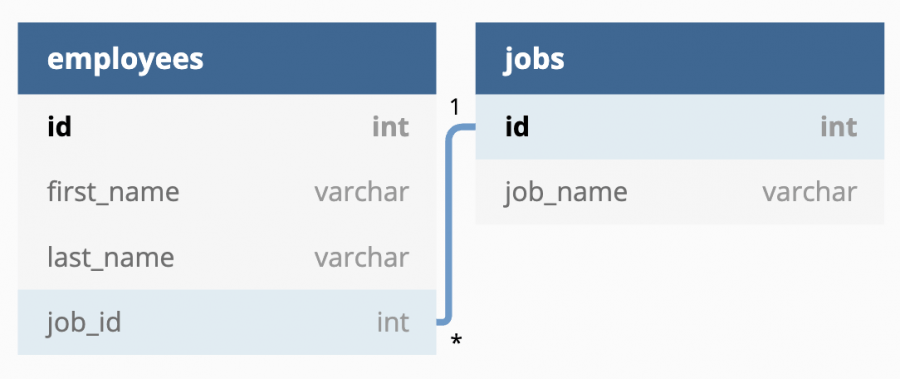
בשיטה הזאת, חסכנו המון מקום. למשל במקום לכתוב Developer Advocate לכל מי שמשמש בתפקיד זה, התפקיד נכתב פעם אחת בטבלת jobs וכל מה שחוזר על עצמו הוא ה – job_id שמפנה אליו לכל עובד בתפקיד זה.
יתרונות נוספים של מבנה זה היו שמירה על Integrity constraints – שימוש רק בנתונים שמבנה הנתונים מאפשר. לדוגמא, אני יכול להקליד כל שם פרטי/משפחה למערכת, אבל לבחור רק מתוך רשימת התפקידים בטבלת jobs, מה שמבטיח נתונים מסודרים ושליפות קלות יותר. זהו חלק ממה שמוכר כ – ACID, ראשי תיבות של Atomicity, Consistency, Isolation, ו-Durability, תכונות המבטיחות את שלמות הנתונים בפעולות מורכבות (תנועות או טרנזאקציות).
שיקולי ביצועים היו משניים ומכיוון שכמויות ה – Data לא היו עצומות (יחד עם המגבלה של 4TB ל – Database) ומבנה הנתונים, אם נעשה בצורה נכונה, הקל על השליפה, זה עבד מצויין (ושופר כל הזמן עם אינדקסים, סוגי Cache שונים, שמירת נתונים בזיכרון ועוד ועוד).
מה השתנה?
עם השנים, כשאפליקציות התמודדו עם יותר מידע, פנו ליותר משתמשים בו זמנית, הפכו להיות גלובליות, נדרשו להחזיר תשובות תוך חלקיק של שניה, הדיסקים הפכו להיות זולים מיום ליום וכח העיבוד גדל משנה לשנה, RDBMS החל להוות מגבלה למפתחים רבים.
עם השנים החלו להופיע מודלים ופתרונות חדשים לשמירת נתונים ומה שהתחיל לפני כעשור בכמה פתרונות לבעיות ספציפיות (כמו בעיית הביצועים של האתר של Amazon בתקופת החגים, שהובילה למאמר של Werner Vogels שהציג לעולם את Dynamo), הפך עם השנים להצפה וכיום יש עשרות ואולי אף מאות כלים שונים, הנכנסים תחת הקטגוריה Database ולנו נשאר רק לבחור את הנכון.
איך בוחרים Database היום?
כבר כמה שנים עולם הפיתוח עובר למטודולוגיה של Puprpose built database. המשמעות היא שלא בוחרים Database לפרויקט החדש שלכם על בסיס הרשיון שכבר רכשתם או בגלל שיש לכם DBA או צוות פיתוח שמתמחה בטכנולוגיה מסויימת או אפילו לא בגלל ששמעתם (או קראתם) שיש Database חדש ומגניב ואתם ממש רוצים לנסות אותו (למרות שזאת סיבה ממש, אבל ממש, טובה).
הבחירה ב – Database כיום צריכה לענות בעיקר על השאלה ״מה ה – Database שהכי מתאים לאפליקציה שאני מפתח?״ ולפעמים התשובה היא יותר מ – Database אחד. כיום, בעולם של Microservices, זאת אפילו לא בעיה גדולה מדי. חלק מה – Services יכולים להשתמש בסוג אחד של Database בעוד חלק אחר, עם דרישות Data שונות, יכול להשתמש בסוג אחר לגמרי.
אז איך בוחרים באמת? הנה כמה שיקולים שכדאי לקחת בחשבון:
סוג המנוע – SQL/NoSQL/Graph/…
יש כיום מספר לא מבוטל של מנועי Database שכדאי להכיר. לכל אחד יתרונות וחסרונות ושימוש נכון בהם יכול לשפר את ביצועי המערכת שלכם, לאפשר לה להתמודד עם כמויות עצומות של משתמשים ולהתמודד עם תקלות ושינויים בצורת השימוש שלכם.
אין לי כוונה לנסות ולסקור את כל מה שקיים היום בשוק אבל הנה כמה סוגי מנועים עיקריים שכדאי מאד להכיר:
Relational Database – RDBMS
עדיין פופלרי ונמצא בשימוש מאד רחב. מנועים מוכרים של סוג Database זה הם MSSQL, Oracle, PostgreSQL, MySQL, Amazon Aurora ועוד. משמש בהמון סוגי מערכות, עם דגש על מערכות כמו מערכות פיננסיות (ודומיהם), בהן יש חשיבות גדולה ל – ACID, שימוש בטרנזאקציות ושמירה על מבנה קבוע ומוגדר מראש של הנתונים. מבחינת ביצועים RDBMS לא מצטיין מול חלק גדול מהאופציות האחרות וסובל בעיקר מירידה בביצועים ככל שיש יותר נתונים וככל שמספר המשתמשים בו זמנית עולה.
NoSQL (Key/Value, Document)
אז אמנם השם לא מדוייק אבל הפך להיות מונח מקובל לכל מה שהוא לא RDBMS. מדובר על המון סוגי מנועים שונים, עם הבדלים גדולים בתכונות אבל בדרך כלל מה שמשותף לכולם, הוא הגמישות בשמירת הנתונים, הן במבנה הנתונים (בהרבה מקרים ללא מבנה נתונים קשיח) והן בצורת השמירה.
שתי משפחות מאד פופולריות הן Key/Value בה שומרים את הנתונים בצמדים של מפתח (מקביל לשם שדה) והערך שלו. למעט מפתח ראשי, כל שאר המפתחות ברשומה ניתנים לשינוי וגמישים לגמרי. השני הוא פורמט Document בו שומרים נתונים במסמך (בדרך כלל JSON) והמנוע יודע לחפש ביעילות במסמכים אלו. גם כאן הגמישות במבנה הנתונים היא מאד גדולה והשימושים מאד מגוונים.
היתרון הגדול של מנועים אלו הוא בביצועים ובמיוחד ביכולת שליפה מאד מהירה, אך מוגבלת, של נתונים, המבוסס על שימוש במפתחות. תשכחו מהעושר שאתם מכירים משפות SQL, היכולת לחבר (Join) בין טבלאות בצורה מורכבת, ביצוע שאילתות משורשרות ועוד כלים שרובנו התרגלנו אליהם. שימוש ב – NoSQL מצריך שינוי מחשבתי וארכיטקטוני אבל הביצועים הם משהו שקשה מאד להשיג (בטח לא לאורך זמן עם גדילה מסיבית בכמות הנתונים ובעומס) מ – RDBMS.
בהזדמנות אני אכתוב על המגוון העצום של מנועים בסגמנט הזה אבל זה דורש פוסט בפני עצמו.
In Memory
תת משפחה של NoSQL בדרך כלל מסוג Key/Value. ההבדל העיקרי הוא שמנועים אלו שומרים את הנתונים בזיכרון ולכן זמן השליפה הוא מאד מהיר. שני הסוגים הפופולריים של In Memory DB הם Memcached ו – Redis. ממש לפני כמה ימים AWS הוציאה שרות חדש בשם Amazon MemoryDB for Redis המפשט את השימוש והאינטגרציה של הפיתרון עם האפליקציות שלכם שרצות ב – AWS.
Graph
משפחה חדשה יחסית של בסיס נתונים, בהם יש דגש גדול על הקשרים בין הנתונים ופחות על הנתונים עצמם. הדוגמא הכי מוכרת של Graph הן רשתות חברתיות, בהן הקשרים בין המשתתפים, תחומי העניין והפעולות שלהם הם הבסיס לחלק גדול של השאילתות (מי מכיר את מי? מי עוד מתעניין בקבוצת הספורט שאני אוהד? וכו׳). שימושים נוספים ל – Graph Database יכולים להיות קטלוגים (פתרון מעולה לתיאור הקשרים בין פריטי הקטלוג כגון חלקי רכבים או ספרים) והמלצות תוכן.
אם זה נשמע מעניין ורלוונטי לשימוש שלכם אבל מעולם לא נתקלתם ב – Graph Database, ממליץ לקרוא על Neo4j או Amazon Neptun.
TimeSeries
אני מוסיף פה נציג לקבוצה שאני קורא לה ״מנועים מתמחים״ – שנבנו במטרה מאד מסויימת לפתרון בעיה מוגדרת, שקשה או יקר לפתור באמצעות מנועים אחרים.
TimeSeries Database הוא פתרון לשמירה של כמויות מאד גדולות של נתונים (יקר בפתרונות אחרים), לא מורכבים במיוחד, שמופקים לאורך זמן (בדרך כלל ממערכות אוטומטית בצורת לוגים או מערכות IoT) ודורשים שליפה מהירה על בסיס פרמטר הזמן. לדוגמא, אם אני מנטר מאות חיישני טמפרטורה במפעל וכל אחד שולח לי מידע כל שניה, אני מקבל אלפי רשומות כל דקה. אם במקביל אני צריך לנתח את המידע, כמו למשל לקבל טמפרטורה ממוצעת לפי חתכי זמן של כל חיישן ושל כל החיישנים יחד, שימוש ב – RDBMS יהיה יקר ואיטי ושימוש ב – NoSQL יכול לתת לי את הביצועים הדרושים, במחיר ממש לא שווה לכל נפש.
זאת רק דוגמא אחת לז׳אנר. יש לא מעט כאלו, כגון שמירת נתונים גאוגרפית (מפות, מקומות) או מנועים המתמחים למשל בכתיבת כמויות עצומות של Data בו זמנית (בעיה שיש במנועים רבים שפשוט יותר לעשות בהם שאילתות Select רבות, מבוזרות ומקבילות אבל מתקשים עם Insert/Update באותן רמות עומס).
Ledger
סביר להניח שאתם מכירים את הקטגוריה הזאת בשם היותר פופולרי שלה – Blockchain. קודם כל נגיד ש – Blockchain != Bitcoin (או כל מטבע קריפטוגרפי אחר). נכון, יש שימוש ב – Blockchain במטבעות קריפטוגרפיים, בגלל התכונות של Ledger Database אבל זה לא אותו דבר.
מדובר על Database, שבנוסף ליכולות רגילות של שמירת נתונים ושליפתם, שומר יומן (Ledger) של כל תנועה שנעשתה עם ה – Data באמצעים קריפטוגרפיים (בקיצור הצפנה). התכונה הזאת מונעת שינוי של נתונים מבלי להשאיר עקבות ולכן אפשר לחזור אחורה ב – Chain ולראות מה קרה עם ה – Data בכל רגע נתון.
שימוש ב – Ledger קיים במערכות פיננסיות, ממשלתיות, רכש וכו׳. ל – AWS יש כיום שרות של Ledger Database הנקרא Amazon Quantum Ledger Database (QLDB).
ביצועים מול עלות
נושא שני שצריך לתת עליו את הדעת, הוא ביצועי המנוע מול העלויות שלו. בעולם ה – Database העלויות הן בדרך כלל של חומרה (או השרות – נדבר על זה בסעיף הבא), רישוי ותפעול.
לגבי רישוי, יש לא מעט אלטרנטיבות OpenSource שכדאי לשקול לפני שמשלמים אלפים רבים (מאד) של דולרים עבור רישוי (לדוגמא להחליף את Oracle ב – PostgreSQL שמאד דומה בתכונות).
לגבי ביצועים, פה הסיפור הרבה יותר מורכב. אתם צריכים לקחת בחשבון המון פרמטרים כגון כמות הנתונים, מספר כתיבות/קריאות ממוצע לשניה, סוג השאילתות (האם ה – Database שלי משמש לשליפת נתונים בזמן אמת, כמו למשל פרטי משתתף במשחק רשת או ניתוח סטטיסטי, כמו כמה אנשים שיחקו במשחק מסויים ב – 24 השעות האחרונות), סוג הנתונים ועוד. אם תבנו מטריצה שנותנת לכם את המידע הזה (בשלב הראשון בקירוב – אחרי שתתנסו עם המערכת הספציפית שלכם אפשר יהיה לדייק אותה) תוכלו לעשות סינון ראשוני של המנועים שמתאימים לכם ומפה לעבור לשיקולי ביצועים מול עלות על מנת לבחור מנוע ספציפי. אם תציצו בעמוד של Databases באתר של AWS, תמצאו רשימה שתעזור לכם לעשות את הסינון הראשוני ומשם לצלול יותר לעומק.
לגבי תפעול, גם כאן הבחירה היא לא פשוטה. יש כמובן את השיקול של ידע קיים. אם יש לכם DBA של Oracle בארגון, יהיה לכם הרבה יותר פשוט לבחור בו מאשר ללמוד MySQL אבל יכול מאד להיות שעלויות הרישוי ישנו את דעתכם. בנוסף התפעול מאד משתנה בין מערכת פשוטה של Database אחד, לבין מערכות מורכבות וקלאסטרים של כמה שרתים, לפעמים בפיזור גיאוגרפי, על מנת לשפר ביצועים ולהגדיל שרידות במקרה של תקלה באחד ה – Nodes.
במקרים כאלו יכול לבוא לעזרתו הסעיף הבא.
שרות או ניהול עצמי
אחרי כל השיקולים הטכניים, זהו לדעתי השיקול החשוב ביותר. כמי שניהל שנים מערכות מורכות של Databases, החל משרת בודד ועד Cluster גלובלי של עשרות שרתים, ניהול של מערכות כאלו הוא מורכב. לא לחינם DBA טוב הוא מרכיב חיוני בכל מערכת כזאת.
עד לפני כמה שנים, לא ממש הייתה אלטרנטיבה. כיום, ניתן למצוא שרותי Database מנוהלים לרבים מהפתרונות עליהם דיברנו. החל מ – Amazon RDS (עליו כתבתי בעבר), שירותי ה – RDBMS המנוהל של AWS, הכוללים תמיכה במגוון גדול של שרותים, דרך שרותי NoSQL דוגמת DynamoDB או Amazon DocumentDB (with MongoDB compatibility) עבור Documents.
בשרות מנוהל, אתם למעשה מורדים מעצמכם חלק גדול מההתעסקות בהגדרה וניהול ה – Database שלכם. זה כולל התקנה, עידכונים, גיבויים, ניהול קלאסטרים, ביצועים ועוד. השרות יעשה את רוב העבודה עבורכם (אחרי הגדרה ראשונית של הצרכים שלכם) וישאיר אתכם פנויים לעבוד על המוצר שלכם.
הבחירה הטבעית שלי בשנים האחרונות היא שרות מנוהל (לא זוכר מתי בפעם האחרונה התקנתי MySQL או דומיו). יש מקרים מאד ספציפיים בהם הייתי שוקל לנהל כיום Database בעצמי. הראשון הוא החלטה להשתמש במנוע שאינו קיים כשרות והשני הוא שיקולי עלות. אם אפשר להוכיח, מספרית, שבמקרה ספציפי העלות הכוללת של שרות היא משמעותית גדולה יותר. גם פה הייתי נזהר מאד, כי בהרבה מקרים קשה לחשב את העלות אמיתית של ניהול עצמי.
הבחירה ב – Database כיום היא בהחלט משימה לא פשוטה. מקווה שנתתי לכם קצת כלים וחומר למחשבה איפה להתחיל. למי שרוצה קצת יותר מידע על איך בוחרים Database, הנה הרצאה שלי מלפני כשנה. אמנם מאז התווספו אפשרויות נוספות אבל הבסיס זהה.
ואם עדיין חסר לכם מידע בנושא, אשמח לשמוע איפה אני יכול להרחיב. תשאירו תגובה פה למטה או צרו איתי קשר.